library(readr)
df <- read_delim("Microdato_Censo2017-Viviendas.csv",
delim = ";", escape_double = FALSE, trim_ws = TRUE)5 Compresión
El almacenamiento de ficheros de datos es un aspecto sumamente importante en todo proyecto de ciencia de datos.
Por ello, en esta sección aprenderemos a transformar un fichero de datos a formato parquet, el cual ofrece un nivel de compresión sumamente elevado.
El formato parquet es un formato de archivo orientado a columnas. Los valores de cada columna se almacenan físicamente en posiciones contiguas, con lo cual se consigue que la compresión de los datos sea más eficiente, al ser los datos contiguos similares. Permite además, usar distintas técnicas de compresión para cada columna, según el tipo de dato.
Para el presente ejemplo utilizaremos la información del Censo de Población y Vivienda del año 2017, alojado por el Instituto Nacional de Estadística de Chile en https://www.ine.gob.cl/estadisticas/sociales/censos-de-poblacion-y-vivienda/censo-de-poblacion-y-vivienda.
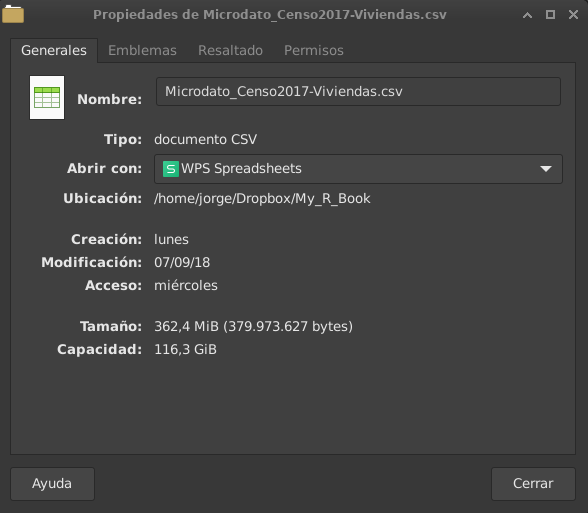
El dataset a importar está en formato CSV y tiene un peso de 362.4 MB.
Exploramos la estructura del dataset
library(dplyr)
glimpse(df)Rows: 6,499,574
Columns: 20
$ REGION <dbl> 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, …
$ PROVINCIA <dbl> 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 1…
$ COMUNA <dbl> 15202, 15202, 15202, 15202, 15202, 15202, 15202, 15202, …
$ DC <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ AREA <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
$ ZC_LOC <dbl> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,…
$ ID_ZONA_LOC <dbl> 13225, 13225, 13225, 13225, 13225, 13225, 13225, 13225, …
$ NVIV <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ P01 <dbl> 3, 1, 1, 1, 3, 3, 3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 3, 3,…
$ P02 <dbl> 1, 3, 1, 4, 4, 4, 4, 3, 1, 1, 2, 4, 1, 3, 4, 1, 1, 1, 1,…
$ P03A <dbl> 5, 98, 5, 98, 98, 98, 98, 98, 5, 5, 98, 98, 5, 98, 98, 5…
$ P03B <dbl> 3, 98, 3, 98, 98, 98, 98, 98, 3, 3, 98, 98, 3, 98, 98, 3…
$ P03C <dbl> 5, 98, 5, 98, 98, 98, 98, 98, 5, 4, 98, 98, 4, 98, 98, 5…
$ P04 <dbl> 1, 98, 2, 98, 98, 98, 98, 98, 1, 1, 98, 98, 1, 98, 98, 1…
$ P05 <dbl> 4, 98, 3, 98, 98, 98, 98, 98, 4, 4, 98, 98, 4, 98, 98, 3…
$ CANT_HOG <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1,…
$ CANT_PER <dbl> 1, 0, 4, 0, 0, 0, 0, 0, 4, 1, 0, 0, 3, 0, 0, 3, 8, 1, 1,…
$ REGION_15R <dbl> 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, …
$ PROVINCIA_15R <dbl> 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 1…
$ COMUNA_15R <dbl> 15202, 15202, 15202, 15202, 15202, 15202, 15202, 15202, …table(df$REGION)
1 2 3 4 5 6 7 8 9 10
117814 196360 121101 308616 788830 354324 411211 573598 381170 332935
11 12 13 14 15 16
44726 65641 2378490 153990 76204 194564 Ahora exportaremos el dataset a formato parquet
library(arrow)
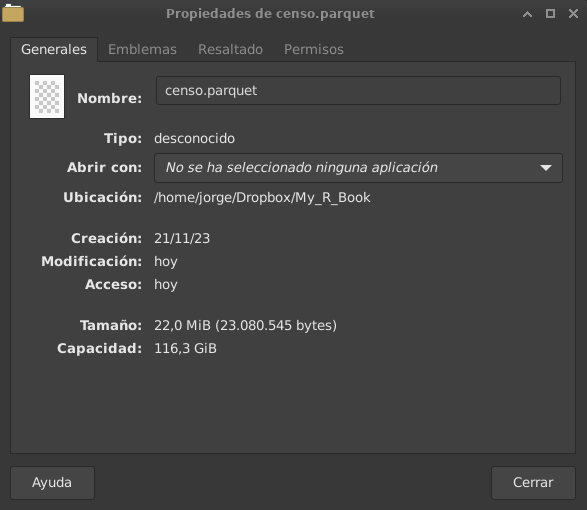
write_parquet(df, "censo.parquet")Podemos verificar que el archivo exportado a formato parquet pesa (en el disco duro) solo 22.0 MB. Es decir, menos del 10% del archivo original.
Ahora importaremos el archivo exportado y corroboraremos que se puede hacer uso de él.
df_censo <- read_parquet("censo.parquet", as_tibble = TRUE)
glimpse(df_censo)Rows: 6,499,574
Columns: 20
$ REGION <dbl> 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, …
$ PROVINCIA <dbl> 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 1…
$ COMUNA <dbl> 15202, 15202, 15202, 15202, 15202, 15202, 15202, 15202, …
$ DC <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ AREA <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,…
$ ZC_LOC <dbl> 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,…
$ ID_ZONA_LOC <dbl> 13225, 13225, 13225, 13225, 13225, 13225, 13225, 13225, …
$ NVIV <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ P01 <dbl> 3, 1, 1, 1, 3, 3, 3, 3, 3, 1, 1, 1, 1, 1, 1, 1, 1, 3, 3,…
$ P02 <dbl> 1, 3, 1, 4, 4, 4, 4, 3, 1, 1, 2, 4, 1, 3, 4, 1, 1, 1, 1,…
$ P03A <dbl> 5, 98, 5, 98, 98, 98, 98, 98, 5, 5, 98, 98, 5, 98, 98, 5…
$ P03B <dbl> 3, 98, 3, 98, 98, 98, 98, 98, 3, 3, 98, 98, 3, 98, 98, 3…
$ P03C <dbl> 5, 98, 5, 98, 98, 98, 98, 98, 5, 4, 98, 98, 4, 98, 98, 5…
$ P04 <dbl> 1, 98, 2, 98, 98, 98, 98, 98, 1, 1, 98, 98, 1, 98, 98, 1…
$ P05 <dbl> 4, 98, 3, 98, 98, 98, 98, 98, 4, 4, 98, 98, 4, 98, 98, 3…
$ CANT_HOG <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1,…
$ CANT_PER <dbl> 1, 0, 4, 0, 0, 0, 0, 0, 4, 1, 0, 0, 3, 0, 0, 3, 8, 1, 1,…
$ REGION_15R <dbl> 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, …
$ PROVINCIA_15R <dbl> 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 152, 1…
$ COMUNA_15R <dbl> 15202, 15202, 15202, 15202, 15202, 15202, 15202, 15202, …table(df_censo$REGION, useNA = "alw")
1 2 3 4 5 6 7 8 9 10
117814 196360 121101 308616 788830 354324 411211 573598 381170 332935
11 12 13 14 15 16 <NA>
44726 65641 2378490 153990 76204 194564 0 Algo importante a mencionar es que el uso de este método de compresión reduce el espacio usado en el disco duro, más no el uso en la memoria RAM. Es decir, cuando ejecutamos la función read_parquet, el archivo se importa al espacio de trabajo de R con su peso sin compresión.