library(readxl)
pobr <- read_excel("AnexoPobreza.xlsx")3 Mapas
Seguramente has visto mapas temáticos en las publicaciones del INEI, como el Mapa de Pobreza Monetaria 2018 (https://www.inei.gob.pe/media/MenuRecursivo/boletines/mapa-de-pobreza-25022020_ponencia.pdf) u otros de diversas temáticas en páginas de otras instituciones. En esta sección te mostraré como elaborarlos tú mismo.
Partamos del siguiente mapa, cuya información se puede obtener de https://www.inei.gob.pe/media/MenuRecursivo/publicaciones_digitales/Est/Lib1718/Anexos.xlsx

Una vez trabajado el archivo de Mapa de Pobreza 1 lo podemos importar a R.
library(dplyr)
glimpse(pobr)Rows: 1,874
Columns: 9
$ Ubigeo <chr> "010101", "010102", "010103", "01010…
$ Departamento <chr> "AMAZONAS", "AMAZONAS", "AMAZONAS", …
$ Provincia <chr> "CHACHAPOYAS", "CHACHAPOYAS", "CHACH…
$ Distrito <chr> "CHACHAPOYAS", "ASUNCIÓN", "BALSAS",…
$ Población_proyectada_2020 <dbl> 39051, 278, 1180, 702, 589, 1933, 53…
$ Intervalo_de_confianza_Inferior <dbl> 5.773728, 25.308002, 36.793306, 27.9…
$ Intervalo_de_confianza_Superior <dbl> 12.29552, 47.73190, 54.67262, 50.392…
$ Grupos_robustos <dbl> 19, 10, 8, 10, 6, 7, 8, 11, 8, 14, 9…
$ Ubicación_pobreza_monetaria_total <dbl> 1747, 852, 506, 754, 261, 315, 581, …El dato del UBIGEO será crucial para combinar esta información estadística con la información georeferenciada.
Crearemos una columna con la agrupación que queremos representar en el mapa. En este caso, utilizaremos la información del Cuadro 4 (página 40) del documento https://www.inei.gob.pe/media/MenuRecursivo/publicaciones_digitales/Est/Lib1718/Libro.pdf para agrupar los grupos robustos por el rango de pobreza monetaria total.
pobr$RangoPobreza <-
case_when(pobr$Grupos_robustos>=15 & pobr$Grupos_robustos<=28 ~ "Menor a 20%",
pobr$Grupos_robustos>=10 & pobr$Grupos_robustos<=14 ~ "De 20% a 39.9%",
pobr$Grupos_robustos>=6 & pobr$Grupos_robustos<=9 ~ "De 40% a 59.9%",
pobr$Grupos_robustos>=1 & pobr$Grupos_robustos<=5 ~ "De 60% a más")pobr$RangoPobreza <- ordered(pobr$RangoPobreza,
levels=c("Menor a 20%",
"De 20% a 39.9%",
"De 40% a 59.9%",
"De 60% a más"))
table(pobr$RangoPobreza, useNA="alw")
Menor a 20% De 20% a 39.9% De 40% a 59.9% De 60% a más <NA>
476 662 594 142 0 La información georeferenciada del Perú a nivel de región, departamento, provincia y distrito la podemos obtener del paquete mapsPERU.
library(mapsPERU)For examples, please visit https://github.com/musajajorge/mapsPERUdf <- map_DISTImportamos el paquete sf para poder visualizar correctamente los multipolígonos.
library(sf)
glimpse(df)Rows: 1,891
Columns: 13
$ COD_REGION <chr> "010000", "010000", "010000", "010000", "010000", "01…
$ COD_DEPARTAMENTO <chr> "010000", "010000", "010000", "010000", "010000", "01…
$ COD_PROVINCIA <chr> "010100", "010100", "010100", "010100", "010100", "01…
$ COD_DISTRITO <chr> "010101", "010102", "010103", "010104", "010105", "01…
$ REGION <chr> "Amazonas", "Amazonas", "Amazonas", "Amazonas", "Amaz…
$ DEPARTAMENTO <chr> "Amazonas", "Amazonas", "Amazonas", "Amazonas", "Amaz…
$ PROVINCIA <chr> "Chachapoyas", "Chachapoyas", "Chachapoyas", "Chachap…
$ DISTRITO <chr> "Chachapoyas", "Asunción", "Balsas", "Cheto", "Chiliq…
$ REGION_NATURAL <chr> "Sierra", "Sierra", "Selva", "Sierra", "Sierra", "Sie…
$ POBLACION_2025 <dbl> 41843, 269, 1125, 716, 554, 1872, 551, 1538, 3279, 37…
$ coords_x <dbl> -77.8566, -77.7431, -77.9491, -77.6773, -77.7558, -77…
$ coords_y <dbl> -6.2477, -5.9963, -6.8077, -6.2979, -6.0784, -6.9349,…
$ geometry <MULTIPOLYGON [°]> MULTIPOLYGON (((-77.8858 -6..., MULTIPOL…Ahora combinaremos la información de pobreza monetaria con el data.frame de información georeferenciada. Para ello, usaremos como campo común el COD_DISTRITO o UBIGEO.
df <- inner_join(df, pobr, by=c("COD_DISTRITO"="Ubigeo"))Para no hacer tan cargado el mapa, filtraremos solo una región.
df <- df |>
filter(REGION=="Puno")Ahora elaboramos el mapa temático con el paquete ggplot2. Nótese que estamos usando geom_sf y para ello fue necesario importar el paquete sf.
library(sf)
library(ggplot2)
ggplot(df, aes(geometry=geometry)) +
geom_sf(aes(fill=RangoPobreza)) 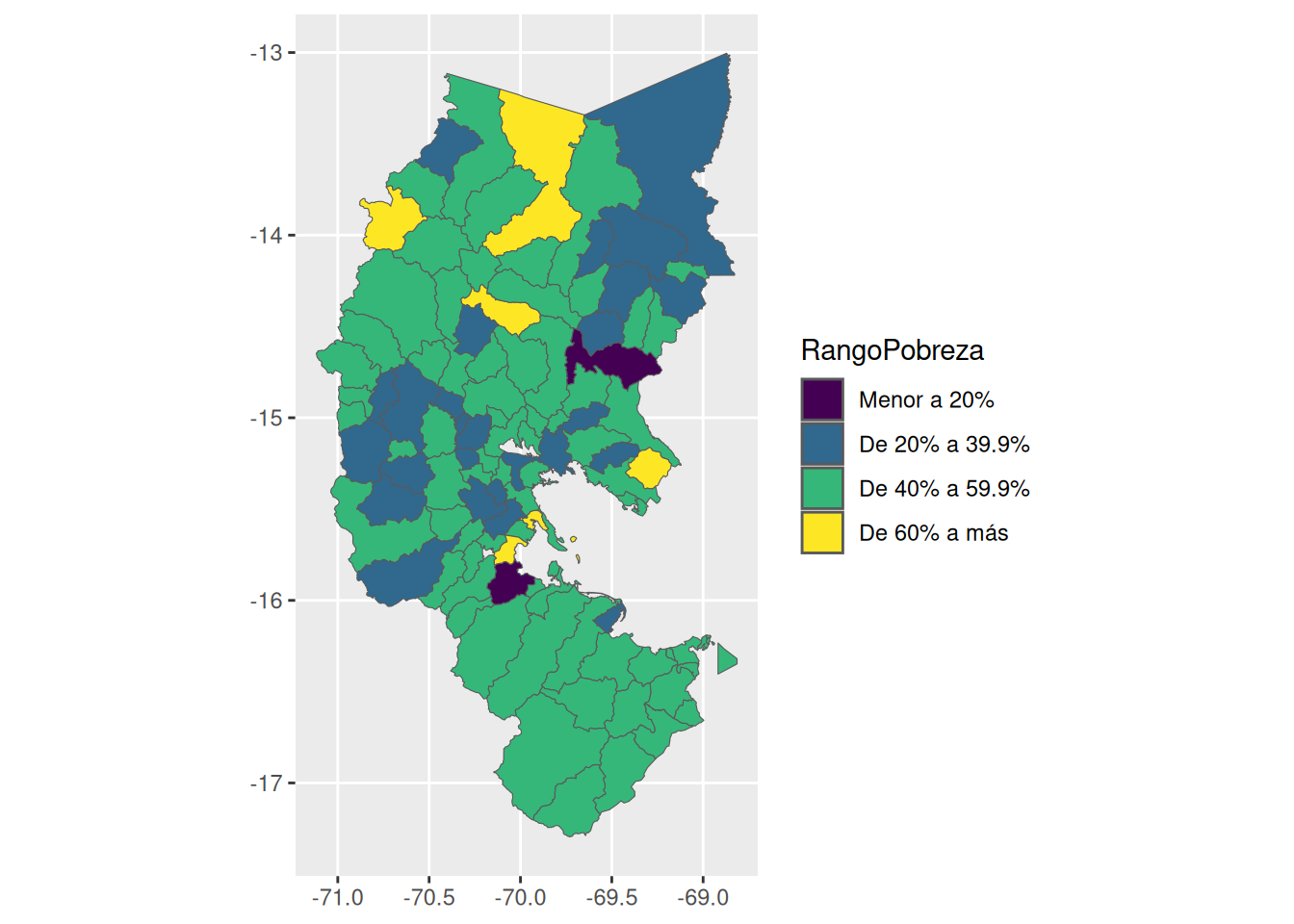
Por supuesto, podemos personalizar aún más el mapa.
colores <- c('#feebe2','#fbb4b9','#f768a1','#ae017e')
library(sf)
library(ggplot2)
ggplot(df, aes(geometry=geometry)) +
scale_fill_manual(values=colores) +
geom_sf(aes(fill=RangoPobreza)) +
labs(fill = "Rango de pobreza monetaria 2018",
title = "Mapa de Puno")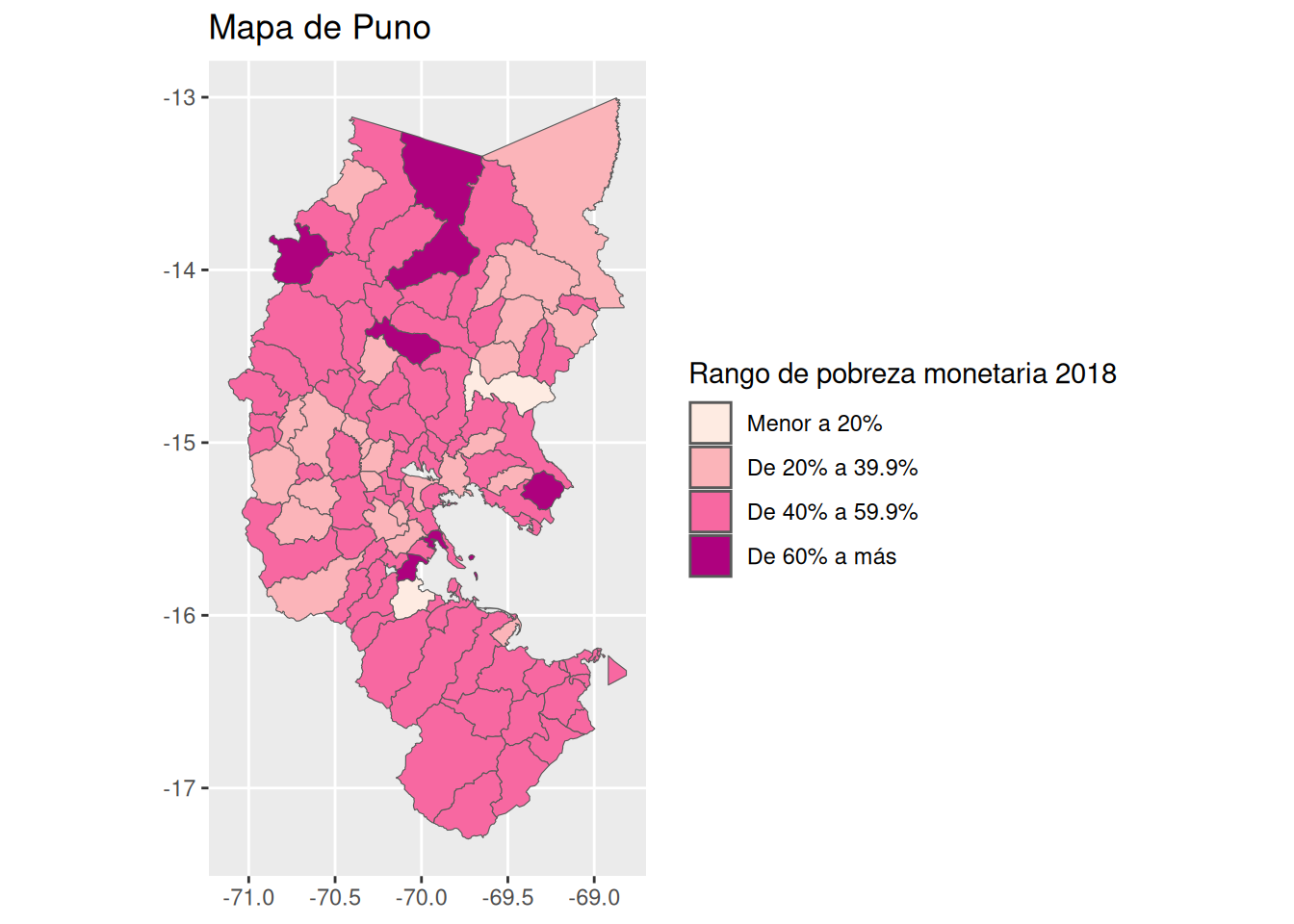
3.1 Mapa dentro de otro mapa
Es bastante común querer elaborar mapas a nivel de región, donde los tamaños de Lima Metropolitana y Callao son demasiado pequeños en relación a las demás regiones. Para ello, conviene insertar un mapa específico de Lima Metropolitana y Callao como miniatura dentro del mapa global a nivel de región.
He aquí un ejemplo. Usaremos la población 2025 que viene incluída en el paquete mapsPERU.
Categorizamos a la población y asignamos colores.
library(mapsPERU)
library(sf)
df <- map_REG
df$Categoría <- cut(df$POBLACION_2025, right=F,
breaks=c(0, 250000, 500000, 1000000,
1500000, 2000000, 2500000,
Inf),
labels=c("[ 0 - 250 mil >",
"[ 250 mil - 500 mil >",
"[ 500 mil - 1 millón >",
"[ 1 millón - 1.5 millones >",
"[ 1.5 millones - 2 millones >",
"[ 2 millones - 2.5 millones >",
"[ 2.5 millones - ∞ >")
)
library(dplyr)
df = df |>
mutate(
color = case_when(
Categoría=="[ 0 - 250 mil >" ~ '#fff5f0',
Categoría=="[ 250 mil - 500 mil >" ~ '#fee0d2',
Categoría=="[ 500 mil - 1 millón >" ~ '#fcbba1',
Categoría=="[ 1 millón - 1.5 millones >" ~ '#fc9272',
Categoría=="[ 1.5 millones - 2 millones >" ~ '#fb6a4a',
Categoría=="[ 2 millones - 2.5 millones >" ~ '#ef3b2c',
Categoría=="[ 2.5 millones - ∞ >" ~ '#cb181d'
)
)Elaboramos dos mapas. Uno considerando todas las regiones a excepción de Lima Metropolitana y Callao, y otro mapa solo para Lima Metropolitana y Callao.
colores = sort(unique(df$color), decreasing = T)
library(ggplot2)
library(sf)
ds = df |>
dplyr::filter(REGION == "Lima Metropolitana" | REGION == "Callao")
df$REGION <- ifelse(df$REGION=="Lima Metropolitana" |
df$REGION=="Callao",
NA, df$REGION)
library(ggrepel)
p1 <- ggplot(df, aes(geometry=geometry)) +
scale_fill_manual(values=colores)+
geom_sf(aes(fill=Categoría)) +
geom_text_repel(mapping = aes(coords_x, coords_y, label=REGION),
size=2.25, min.segment.length=0, max.overlaps = 200,
color="black") +
labs(x="", y="") +
labs(fill='') +
theme(legend.key.size = unit(0.5,'cm'),
legend.text = element_text(size = 7))
p2 <- ggplot(ds, aes(geometry=geometry)) +
scale_fill_manual(values=unique(ds$color))+
geom_sf(aes(fill=Categoría)) +
scale_x_continuous(expand=c(0,0)) +
scale_y_continuous(expand=c(0,0)) +
geom_text_repel(mapping = aes(coords_x, coords_y, label=REGION),
size=1.75, min.segment.length=0, max.overlaps = 200, color="black") +
labs(x="", y="") +
labs(fill='') +
theme(legend.position='none') +
theme(
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_blank(),
axis.ticks.y = element_blank()
)Unimos ambos mapas.
library(cowplot)
ggdraw(p1) +
draw_plot(p2, width = 0.30, height = 0.28, x = 0.11, y = 0.10)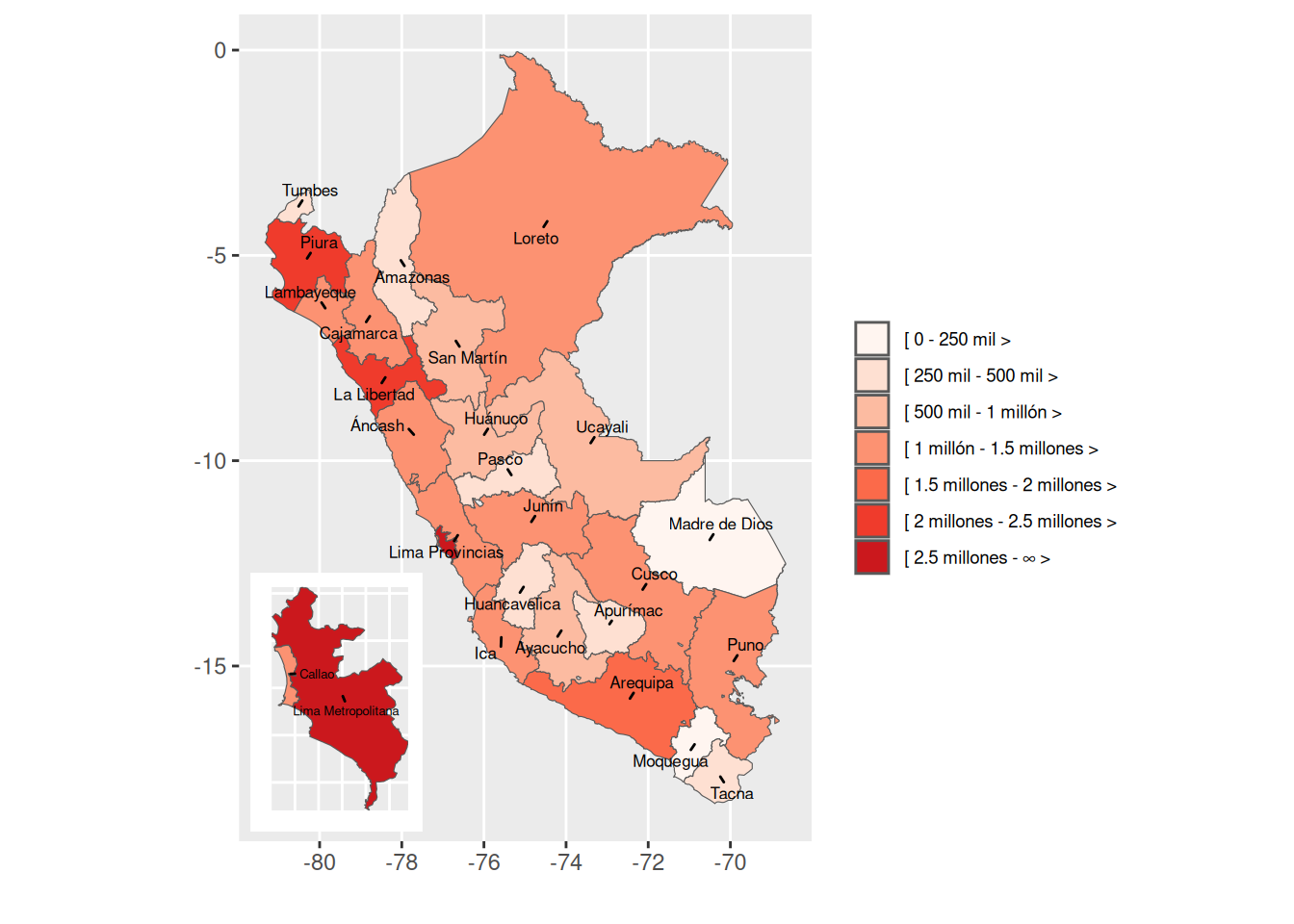
El archivo trabajado se puede descargar en https://zenodo.org/records/10564373↩︎